Critical sets in Futoshiki Squares
On January 4, 2012, as part of an MAA special session on the Mathematics of Sudoku and other Logic Puzzles at the Joint Mathematical Meetings in Boston, I gave a talk about critical sets in Futoshiki squares. I wouldn’t say I generated any groundbreaking results, but I showed that a new problem has some interesting aspects to it, and if it gets people thinking more about puzzle-related combinatorics, mission accomplished.
Slides (plus a couple of bonus puzzles I prepared for the session) can be found on this page under “The Mathematics of Puzzles.” I’m very open to talking about this and related problems, so do get in touch with me if the slides inspire anything.
Note: If you happen upon this entry after July 2012 and the link above doesn’t lead anywhere, chances are I’ve completed my move to Brown but haven’t updated old entries. If that’s the case, look for me on the Brown website, and the slides are likely linked from my web page there. (If you happen upon this entry after July 2112, greetings from the 21st century! Sorry about that whole global warming thing. We tried our best, but fossil fuels are just so convenient…)
Long time, no blog
Strange days indeed.
The genesis of this blog was an effort to reinvigorate my research program. I have always considered myself a teacher above a researcher, but I have also been holding on to a tenure track position for three years, and in such a position, even at a teaching-focused liberal arts school like Guilford, there is an expectation to produce measurable research progress. So I attempted to post here more often and try to get my ideas in writing, in the hopes that it would keep me motivated and help draw collaborators.
Except after a few months, the blog petered out. And a few things of note happened.
1) After a rather unproductive research summer, I found myself doing an about-face and deciding that at this phase of my career, making independent research a focus was not an efficient use of skills, and thus, I applied to a number of non-tenure-track teaching positions.
2) Laura Taalman and Jason Rosenhouse, in coordination with the release of their excellent (and reasonably priced!) book Taking Sudoku Seriously, organized a session on Sudoku and other pencil puzzles at the Joint Meetings. Given my extracurricular interests, I felt that if there was ever a Joint Meetings session at which I should give a talk, it was this one.
3) While I was waiting to hear from schools I applied to at the end of Item 1, Brown University decided to institute a brand new Lecturer position, which I was offered and accepted for Fall 2012. The aim of this position, among other things, is to add consistently, stability, and vision to the undergraduate calculus program. In addition to teaching two courses a semester, I will be organizing and supporting up to seven calculus courses across the curriculum.
All of this leaves me in certainly an exciting position, but a slightly awkward one when it comes to research… I have now obtained a position where research is not a requirement, which was my goal, but ironically, having prepared my talk for Boston, I’m probably more enthusiastic about research than I have been in some time! But on the other hand, I haven’t really done much actively so far this year, so it’s not as if that enthusiasm is leading toward a paper. But I have a number of people who have expressed interest in collaborating and who have shared ideas, and I find research much easier to approach when it’s not actively being demanded. I’ll probably have a lot less time for research in the new job, but when I do have time, I may be more inclined to work on it than I am now.
The thrust of all of this is that I can’t guarantee this blog will be updated frequently. Certainly when I have research ideas/progress that I think is worth sharing, I’ll drop by and post, but those moments may be few and far between. Really the main reason I showed up now was to post my slides from the Boston talk (see next post), but I figured I should say something about where I’ve been for 6+ months. So after that post, I may be back in less than 6+ months. Or maybe not. Time will tell.
Also, I think I might write a book. But perhaps that’s getting ahead of myself…
To Handout or Not to Handout
Naturally, immediately after posting about who I’m trying to reach with this blog, I stopped trying to reach them for over a month. I blame a complex combination of the statistics course I’m teaching, the National Puzzlers’ League convention, and the lethargy-inducing summer heat for my posting hiatus.
I’ve said this is intended to be primarily a research blog, but with my course coming to an end, teaching is more on my mind (as it often is), so I figure I’ll bring up a pedagogical issue. This summer, I taught Guilford’s Elementary Statistics course for the fourth time. The first time I taught it, I was not in love with the textbook we used (Brase & Brase), and I spearheaded a shift to one of several texts available by Sullivan. This summer, I continued to use Sullivan, but I changed the source of my homework assignments.
Previously I assigned odd-numbered exercises as uncollected practice problems, and even-numbered exercises as homework to be turned in. (Convincing students to complete the uncollected problems is a battle worth discussing in its own future post.) For this course, I still used practice problems from the text, but I started writing my own problem sets to replace the even-numbered problems. There are pros and cons to this approach, some of which I expected, and some of which caught me by surprise.
PROS
Flexibility: When choosing assignments from the book, I often need to comb the exercises carefully to make sure I have a representative sample of the types of obstacles I want my students to be able to navigate (For example, making sure to include a certain number of two-tailed tests, intervals using all different test statistics, probability questions that involve independent and conditional events, and so forth). Some of these then need to be trimmed to create assignments that reflect the concepts I want to teach (do problem #34, but you may ignore this instruction which applies to a concept we had to skip due to time constraints). When writing my own assignments, I can create problems that deal with exactly what I want to cover, no more, no less.
Compatibility with Exams: I have, in the past, received complaints that the style of problems I pose in my exams is different than the problems students have practiced from the book. This argument arises in most of my classes, but in stats more than others, where the problems tend to be wordy and the language is flexible. This semester, since the homework assignments were also written in my style, students no longer expressed frustration about the “language gap” on the exams (although a few complained about the differences in wording between practice problems from the book and the problem sets).
Improved Performance?: The average homework grade in this iteration of the course was higher (by about 3 percent) than in either of the past two semesters. However, there are too many lurking variables to assume the assignments are responsible: the current course is taught in the summer when many students have fewer distractions, we meet twice a week rather than once a week in the fall/spring evening sections, and of course, every class has a different population of students. But while the grade increase can’t automatically be attributed to the different style of homework, at least it didn’t have an obvious negative effect.
Academic Honesty: While Guilford has an honor code, it should surprise no one to hear that it isn’t always followed to the letter. I’ve taught at two schools, and at both I’ve had at least one incident in which a student got their hands on the textbook solutions, which has left me in a paranoid state where every time a student does well, I have to prove to myself that they’re not copying from an external source. Assigning problems that have not previously seen the light of day very effectively stops the paranoia, although to sustain this benefit, the assignments would need to be heavily altered from semester to semester.
CONS
Time: The obvious disadvantage to assembling these assignments is that takes a lot of time to create, typeset, and distribute the problems. This was not hard to fit in this summer when I was teaching one class, but as my three-course load for the fall approaches, trying to prep original handouts for all three courses is daunting. It would presumably be easier to update these assignments once I’ve taught for a long time and I’ve developed a library of problems. But as noted above, keeping the assignments fresh is important if one wants to ensure the solutions aren’t floating around the student community.
Lack of Flexibility: Yes, I know this appears to contradict my pro above. I have a tendency to try to plan in advance as much as possible, so that I have material planned on a week-to-week basis as the course begins, and homework selected a few weeks in advance. Of course, sometimes things don’t go quite according to schedule, and some adaptation is needed… When I was assigning problem numbers from the book, it was trivial to bring up the website and move Problem 48 from Week 5 to Week 6. When I show up for class with a handout already, that’s a bit more etched in stone. This problem solves itself if I’m willing to do less advance planning, but since that’s something I find comfortable, this counts as a con for me.
Distance from Textbook: I already had some issues with students not doing the practice problems (which is fine with me if they don’t need to in order to learn, but most students in the course do), and incidents those seemed to increase this semester, possibly because having the collected problems originate from an entirely different source left some students thinking they didn’t need to open the textbook to succeed. I frequently tried to dissuade them of this notion, but it’s still worth mentioning.
So what to do going forward? (Now that I’ve spent enough time on this entry that I could have already written an assignment?) My fall courses are Statistics, Calculus I, and Multivariable. My current plan is to keep using original homework for stats, and to use book problems for Multivariable, since interesting problems in that course are harder to write, and I have fewer academic dishonesty issues in that course. I’m still very much on the fence about Calculus I. Feel free to push me toward either side.
Target audience
I’m still working on finding a voice for this blog, and I find myself repeatedly asking myself the same question when writing: Who is this blog for? One can ask that question in terms of mathematical maturity, area of expertise, or simply why they might be reading this.
Well, one member of the target audience is me, in the sense that when writing about my own research ideas and questions, putting them in writing (especially in a public forum where there’s some accountability) helps give me focus. Reading the posts back later is often useful as well. But it becomes something of a useless exercise if I don’t have readers, and so I have to pick a certain level to pitch the content at. Some types of readers may have looked at some of my previous entries and stumbled upon terms they didn’t understand… others might have been mildly disgusted that I took the time to (not very rigorously) define a Cayley graph. So let me say a little about where I’m aiming.
It’s important to me to make this blog accessible to people who are not Ph.D-level researchers, and certainly not necessarily in my area. As a dedicated undergraduate teacher, and someone who would like to direct more undergraduate research, I want to be able to send students here so that they can initiate conversations with me about posts they find interesting. If at some point I find myself on the job market, I’d like this to be a place where search committees can get more information about me, and I don’t assume those committee members are number theorists. And thinking in a very general sense, if something is available to everyone on the internet, I like the idea that a random netizen might stumble upon it and be able to read it. So to reach a wide audience, I try to explain things in simpler terms than one would see in the literature. It’s sort of a “popular science” voice without the “popular.”
When I summarize papers and talks, I intentionally don’t give details of the results. This is simply because I don’t think it’s my place to do so, since the findings aren’t mine. I do try to give a feel for the flavor of the arguments, and enough information so that if a reader is interested, they can figure out where to go. On the other hand, when discussing my own work, I tend to be more specific, since I have both the knowledge and the authority (using that term pretty loosely) to do so. If I’m talking about something I’m working on, it means that I’m open to feedback and/or collaboration, so if anything piques your interest, don’t hesitate to comment on it or contact me privately.
As I try to pitch things to this rather broad target audience, I hope people won’t make judgments based on my choice of tone; if, for example, I take more space than strictly necessary to explain a concept, it doesn’t mean that I would require that sort of explanation to grasp it myself. Being a researcher and being a teacher are both complex and difficult arts; just as I have to juggle both as an academic, I have to juggle both when writing here. I hope that if the result is not at the optimal level for you as a reader, you’ll bear with me.
Two potential filing errors
I’ve recently (okay, longer than recently) wondered whether my interest in combinatorial number theory is actually an interest in combinatorics, filtered by a somewhat stubborn background in number theory. To put it differently, growing up I studied a large quantity of number theory and very little combinatorics, and now I find myself quite interested in both. The fact that combinatorics hooked me with a lot less exposure might mean that that’s what I should really be doing…
Anyway, with this in mind, I’ve been making a point to scan the titles regularly on math.CO, which feels like wandering through an unfamiliar neighborhood within your city. I find a lot of the abstracts intriguing, though my repertoire of theorems and terminology is a bit lacking. Notably, however, my most recent pass turned up this paper on sum-product estimates. How in the world is this not cross-listed on math.NT?
Some questions about gerechte designs
A latin square is an n x n arrangement of numbers from 1 to n such that every row and column contains each of the n symbols exactly once. A gerechte framework is a partition of the n x n square into n sets of n cells. A gerechte design for such a framework is a Latin square in which each set in the partition also contains each of the n symbols once. A multiple gerechte framework (and design) is one in which multiple partitions are specified (and satisfied).
The name “gerechte design” was coined by W.U. Behrens, with “gerechte” meaning “fair” in German. Note that if n=9 and the gerechte framework is nine 3×3 subsquares, a gerechte design is a valid Sudoku configuration.
In an attempt to yank things closer to the number theory world, I propose an additional object: A sum-gerechte design is one in which the sets in the framework do not necessarily contain all symbols from 1 to n, but the sum of the symbols must be n(n+1)/2. Note that unlike in the case of gerechte designs, this setting requires the symbols to actually be the integers from 1 to n; in the first paragraph, we could have used any alphabet with n letters without changing the fundamental nature of the definitions.
Some of what’s known: E.R. Vaughan determined that the process of determining whether a gerechte framework admits a gerechte design is NP-complete. Vaughan and Courtiel proved that a framework consisting entirely of rectangles of equal size (though not necessarily oriented the same way) always admits a gerechte design. And as I mentioned in an earlier post, R.A. Bailey, Peter Cameron, and Robert Connelly fully characterized a multiple gerechte design which they called “symmetric Sudoku.” The specific case of Sudoku has been studied by various mathematicians due to its popularity, with many brute-force approaches yielding numerical data, but with many questions remaining open.
Here are some questions I’ve come up with, some of which I’ve thought about, some of which are off the top of my head. If you have insights into them, have seen work on them elsewhere, or you’d simply like to discuss the questions further, don’t hesitate to get in touch with me.
1(a). Given a fixed n, for what numbers m is there an n x n gerechte framework that admits exactly m gerechte designs?
1(b). Given a fixed n, for what numbers m is there an n x n gerechte framework that admits exactly m sum-gerechte designs?
1(c). Given a fixed n, for what numbers m is there an n x n gerechte framework that admits exactly m sum-gerechte designs but no gerechte designs?
1(a) was the first question I asked, in an earlier post on this blog. My by-hand (incomplete) evaluation of 4×4 gerechte designs revealed frameworks admitting 0, 1, 4, 6, 8, 12, and 24 colorings, all of which are factors of the number of possible Latin squares; however, for n = 5 there is at least one framework admitting 20 designs, which is not a factor of the number of Latin squares. I’ve downloaded GAP and the GRAPE and DESIGN packages to try to analyze cases more efficiently, but I haven’t figured out how to use them yet. (And my lack of a UNIX system may be limiting for that software.)
A Bailey-Kunert-Martin paper from 1991 looks at randomization amongst gerechte designs, which should relate to the number of available designs; however, the paper almost exclusively deals with rectangular frameworks, and the approach doesn’t seem to generalize well.
As for 1(c), for n = 5, there is always at least one framework that admits a sum-gerechte design but not a gerechte design; in fact, one can force this to be the case using only three of the rows, and the rest of the framework is unconstrained (but will affect the number of sum-gerechte designs).
2. If each of the sets in a gerechte framework is contiguous (that is, it is an unbroken collection of adjacent cells), does the framework necessarily admit a gerechte design?
Vaughan also asks this question in the final section of his paper, The complexity of constructing gerechte designs. I conjecture that the answer is yes, and I hope there may be an inductive method to build a design in this situation. I spoke to Vaughan, and he found a simple 6×6 framework with contiguous regions that cannot be filled. He is still, however, interested in the question of whether the decidability problem is NP-complete when restricting to frameworks of contiguous regions.
3. Given a “Latin gerechte framework” (one in which no two cells in the same set are in the same row or column), what can we say about the set of sum-gerechte designs?
This is a generalization of the traditionally studied area of orthogonal latin squares, which are gerechte designs from Latin frameworks. For example, when n=6, no such gerechte designs exist, but perhaps there are sum-gerechte designs.
4. In the Vaughan-Courtiel paper, the authors quote a result by Hilton that says an (S,T,U)-outline Latin square can be always be lifted to a Latin square. Is there a reliable way to determine how many such Latin squares amalgamate to a given (S,T,U)-outline Latin square?
An (S,T,U)-outline Latin square essentially involves condensing the rows, columns, and/or alphabet into fewer than n classes, and then placing multiple symbols per cell to compensate. The Hilton paper is from 1987, and I haven’t actually checked to see whether he considers the counting problem. It’s possible this question has already been answered.
5(a). What multiple gerechte frameworks admit gerechte designs? Unique gerechte designs? Sum-gerechte designs?
5(b). In the gerechte case, each set has to contain {1,…,n}, and in the sum-gerechte case each set can contain any set of numbers that sum to n(n+1)/2. Suppose we specify another set of acceptable n-tuples. Are there constraints that lead to interesting problems?
5(a) and 5(b) are both extremely general, perhaps too much so to yield any interesting results. But I figured they were worth cataloguing here.
Scenes from CANT 2011
My plan to post blog entries from my hotel room in New York didn’t work out as intended, mainly because I brought my iPad instead of my laptop. While the tablet makes a good substitute for a computer in a lot of ways, I’m still not comfortable writing long documents on it. It’s now a few days later, and I’m going to do my best to translate my massive sheafs of notes into some comments about the workshop. I was originally going to try to say something about all of the talks, but to maximize the possibility that this post actually gets finished, I’m going to narrow it down to some of the pieces I found most interesting/accessible.
In my last post, I talked about reading some of Giorgis Petridis‘s papers so that I would be able to follow parts 3 and 4 of his series of his talks; the material he presented was almost exclusively from those papers, so I don’t have much to mention contentwise that I didn’t already say. I will add that Giorgis was a very eloquent speaker, and I enjoyed speaking with him throughout the conference.
Both of the days I attended started off with talks involving factorization theory (which is discussed in Chapter 1 of Geroldinger/Ruzsa’s Combinatorial Number Theory and Additive Group Theory, but ironically I skipped to Chapter 2). One of the main ideas in this area is generalizing the concept of a unique factoization domain to deal with possible factorization lengths. For example, if E is the set of all even numbers, E doesn’t have unique factorization, but any two factorizations of the same element into irreducibles results in the same number of irreducibles. Other rings don’t have this property, and one can look at the elasticity of elements (largest factorization length divided by smallest) and of the ring (supremum over all element elasticities).
Scott Chapman talked about block monoids, algebraic objects that arise from studying factorization in number fields. Studying the structure of these objects allows one to determine the Davenport constant, which provides a route into the elasticity of the ring integers in the corresponding number field. On Friday, Paul Baginski presented some results on multiplicatively closed arithmetic progressions, like the even-numbers example above. He also defined the terms accepted elasticity (the supremum occurs as the elasticity of an element) and full elasticity (every rational number below the supremum occurs). Accepted elasticity obviously fails if the elasticity is infinite or irrational, but interestingly, Paul mentioned an example, {4+6x}, in which the elasticity is 2 but it is not accepted.
Alex Kontorovich presented some material on a conjecture by Zaremba that has come up in his work on Apollonian circle packing with Jean Bourgain. The initial question is whether, given a prime d and a primitive root b (mod d), the points

This means it’s of interest to know what denominators occur in continued fractions for which numbers in the expansion are bounded. Zaremba’s conjecture states that once you raise the bound to A=5, any natural number can occur as a denominator. It is known that A=4 isn’t sufficient, as no rational number with a denominator of 54 has a continued fraction expansion without exceeding 4. Alex went on to share a conjecture by Hensley that ties the bound to Hausdorff dimension of the set of fractions with bounded expansions, a counterexample to that conjecture, and some new bounds involving Hausdorff dimension that do work.
Steven J Miller asked me not to go into detail about his results in this blog, as a lot of his current research is done with undergraduates, and he didn’t want me to cause anyone to beat his students to the punch. Suffice it to say that Steve and his students are continuing to find interesting results about MSTD (More Sums Than Differences) sets. These are sets in which, contrary to expectation, the difference set A – A is smaller than the sumset A + A. Most of the initial results about these sets were probabilistic in nature, as one can fix the extreme portions of the sets and then show that a positive proportion of the possible choices for the middle result in a MSTD set. But the new progress involves construction of explicit sets, and some exploration of (kA+kA) vs. (kA-kA).
In memory of the recent passing of Yahya Ould Hamidoune, Mel Nathanson (the conference host) gave a series of talks discussing Hamidoune’s graph-theoretic approaches to additive combinatorics questions. The approach involves Cayley graphs (graphs constructed from a group G, with edges determined by pairs differing by elements of a subset S). Vertex sets which are sufficiently large and separated from a sufficiently large vertex sets, and which are minimal with respect to these constraints, are known as k-atoms, and the strong requirements result in useful theorems that can be applied to k-atoms. In the final lecture, Mel used these theorems to prove the Cauchy-Davenport theorem for sumsets mod p. There is a more detailed treatment of Hamidoune’s work over at Terry Tao’s blog in this entry.
These are some of the main talks I wanted to mention… I may add some more later, but for now I’m going to cut myself off.
Petridis’s explorations of Plunnecke
As Tim Gowers trumpeted in this blog entry, Giorgis Petridis has been tinkering with the additive number theory applications of Plunnecke’s Inequality (please excuse my lack of umlaut, since I suspect I’m going to be repeating that name a lot and don’t want to hunt down the HTML tags). Petridis is giving a four-part talk at CUNY this weekend, and since I’ll be missing parts one and two, I’ve been rummaging through his recent papers on the arXiv, in the hopes that I can have some idea what’s going on on Thursday.
Plunnecke’s Inequality concerns a particular type of graph, called a Plunnecke graph or occasionally a commutative graph. Plunnecke graphs are directed graphs with vertices in a sequence of tiers (V0, V1, V2,…), such that each edge goes from one tier to the next tier, and any pattern of edges
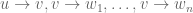
“factors” into a separated pattern of edges
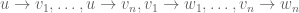
where the vi‘s are distinct. The relevance of this type of graph to additive number theory is as follows: if A and B are subsets of an additive group, and one sets the Vh to be the sumset A+hB, and the edges from elements in any tier to elements in the next tier that arise from adding an element of B, one ends up with a Plunnecke graph (due to the commutativity of the elements).
Plunnecke’s Inequality involves the magnification ratio from V0 to Vh: Look at a set X in V0, and take the number of vertices in Vh on paths from X, divided by the number of vertices in X. The magnification ratio Dh is the ratio which is smallest over all choices for X. The big inequality states that Dh1/h decreases as h increases. This leads to many of the most standard inequalities to control sumset size, such as the following, due to Imre Ruzsa:
If


This is all old news, but the point is that Plunnecke’s Inequality is proven as a pure graph theory problem, using an application of Menger’s Theorem. Petridis’s surprising discovery was that one can prove Ruzsa’s inequality without the detour into graph theory, via an induction proof. Maybe it doesn’t seem surprising that one doesn’t have to use graphs to prove a problem which is not inherently about graphs, but the source of the surprise is that for about twenty years, nobody happened upon the non-detour proof. I won’t take the time to summarize the argument, because Gowers (Petridis’s graduate advisor) already did a fine job doing so in his aforementioned blog entry. Suffice it to say that it utilizes the extra traction one achieves by assuming you have already chosen the right X in the magnification ratio description above.
I haven’t read all three of Petridis’s papers in their entirety (yet). The one I found most interesting is graph-theory-based and presents a new proof of Plunnecke’s Inequality that does not require Menger’s Theorem. I’m not sure whether the arguments arose from translating the induction argument into the graph setting, or were simply inspired by the revelation that Menger was not needed in the additive setting and thus might not be required to prove Plunnecke; either way, the paper gives easy-to-follow proofs, and it explores the sharpness of Plunnecke’s Inequality by identifying what happens when the magnification ratios constitute a geometric sequence.
The argument summarized in Gowers’ entry appears in a more general setting in this paper, which looks at product-sets in a non-abelian setting. The results for product-sets are obviously weaker than in the sumset case, but the first theorem introduced is strong enough to make up most of the improved proof of Ruzsa’s result. The third paper is a bit more daunting, but I intend to give it a look on the plane Thursday morning. Hopefully this reading will give me enough background to follow at least part of what Giorgis has to say after I arrive at CUNY this weekend.
Some Papers I’ve Read Recently (May 2011)
As promised, some thoughts on a few of the papers I’ve been reading. (Mostly I’ve been working my way through recent issues of INTEGERS to get some breadth, although I’ve also been pursuing material on gerechte designs, and I intend to read the recent papers by Giorgis Petridis so I can understand his third and fourth talk at CANT.)
Unbounded Discrepancy in Frobenius Numbers – Jeffrey Shallit, James Stankewicz
Frobenius numbers are a generalization of an example I’ve always liked to use in elementary number theory classes, which I refer to as the McNugget problem even though McDonald’s has ruined it for me by changing their serving sizes. The example is, “If McDonald’s serves 6, 9, and 20-piece McNugget orders, what is the largest n such that you cannot order exactly n nuggets?” (I came up with this question myself as a child, but since {6,9,20} is used as an example in this paper, I was clearly not the only one!)
The Frobenius number g0(x1,…,xn) is asks this same question for general sets of integers. There is a generalization gk which asks for the largest n that has exactly k representations as a sum of elements (with repetition) in the set. The authors present sets for which gk can be (surprisingly?) arbitrarily larger than g0, along with some related results.
To me, the most intriguing part of the paper is a conjecture toward the end. Let f(k) be the least non-negative integer i such that gi > gi+1 for some nontrivial set of size k (nontrivial in a particular way specified in the paper). f(k) is known for k > 3, but f(3) is unknown, and a set of data produced by the authors suggests that f(3)=14.
Van der Waerden’s Theorem and Avoidability in Words – Yu-Hin Au, Aaron Robertson, Jeffrey Shallit
I tend to gravitate toward topics involving both combinatorics and number theory, and combinatorics on words has mostly escaped my notice since it seemed more purely combinatorial. I was unaware, however, of additive questions in the subject. The question that drives this paper is an open problem asking whether one can construct an infinite sequence (or “word”) of integers that avoids consecutive blocks with the same length and sum. The authors apply van der Waerden’s Theorem on arithmetic progressions (which has a Ramseyesque feel to it but has a straightforward proof by induction) to obtain some results on variants of this problem, mainly looking at sums reduced mod k.
The arguments used in the proofs, involving recursively defined words and block arguments, gave me a nice sense of how theorems are approached in this area of study. Also, given my previous experience with being “scooped” by others independently working on the same problem and obtaining stronger results, the authors’ addendum describing a similar situation made me feel like less alone in that experience. So that was nice.
Diophantine Equations of Matching Games I – Chun Yin Hui, Wai Yan Pong
This paper and its sequel (written by Pong and Roelof J. Stroeker) concern games in which a player draws d balls from a bag containing balls of n colors. The goal is to determine, given n and d, what color distributions result in a 50% chance of drawing a monochrome set, which boils down to finding positive solutions to a Diophantine equation depending on n and d. The first paper studies the d=2 case with arbitrary n, while the second paper sets n=2 and looks at d=3,4,5.
The first paper quickly demonstrates that solutions recursively generate more solutions, and the authors make some interesting observations about the graph of solutions (where edges indicate the recursive step), which is connected for n=3 but not for n > 3. The conclusions are nontrivial, but I wish I’d had this problem in my back pocket when I taught my number theory class this year, as the recursive approach would have been a nice “higher-dimensional” companion to our study of solutions to Pell’s Equation. I haven’t read the second paper yet, but an initial glance suggests it is a lot more number-theoretical, as the Diophantine equation will necessarily be of higher degree, and the paper subsequently involves some discussion of elliptic curves.
Sudoku, gerechte designs, resolutions, affine space, spreads, reguli, and Hamming Codes – R.A. Bailey, Peter Cameron, Robert Connelly
Since realizing that “irregular sudoku” are actually already part of the literature as “gerechte designs,” I’ve been seeking out every paper I can on the subject. The original paper that introduces the concept, by Behrens, is unfortunately (for me) in German, and Bailey’s papers from the Journal of Agronomy and Crop Science are a little more focused on statistics than I’d like. But I very much enjoyed this paper, which is primarily focused on a particular multiple gerechte design, which the authors describe as “symmetric sudoku.” This variant outlaws repeated digits in rows, columns, subsquares, and then three more partitions (including, for example, the nine sets each consisting of all the squares in a fixed position within their subsquares).
These additional constraints give the solutions enough structure to bring coding theory into the mix, as any solution can be shown to correspond to a perfect code on

I’m still very interested in the question of what numbers of solutions can occur for an n x n gerechte design; this may or may not be a question that others would also be interested in. Either way, my reading on the subject suggests that to catch up with others studying gerechte designs, I need to familiarize myself with the GAP/GRAPE/DESIGN computing systems, so that I can bypass some of the counting-by-hand I’ve been doing. So that’s a goal for the near future, though it will have to wait until I get a functioning AC adapter to bring my laptop back to life.
CANT 2011 Preview
Guilford held their commencement on May 7, and since then I’ve spent most of my time in Providence. Despite being on vacation, I did a decent job on the reading front, though less so on the blogging front (and my laptop’s AC adapter dying hasn’t helped matters). I’m back in Greensboro now, and I do intend to write something about some papers I’ve recently looked at, hopefully going up by tomorrow.
Three years ago, I attended and presented at the Combinatorial and Additive Number Theory Workshops at CUNY, and I found the meetings very interesting and enjoyable. Since then, I haven’t managed to attend due to scheduling conflicts. The same is partially true this year, since I’m teaching statistics twice a week this summer, but Steven J. Miller convinced me that half a conference is better than no conference at all, so I’ll be attending two-minus-epsilon of the four days of this year’s event, next Thursday and Friday. (The value of epsilon depends on the efficiency of US Airways and New York City taxis on Thursday morning.)
Unfortunately, three of the talks are split into four parts over the course of four days, so I expect to be a bit disoriented during those sessions, having missed the lead-ins. Still, I’m hopeful that I’ll be able to observe and talk about some good mathematics, and I intend to report on some/all of the proceedings here. (In the very unlikely event that you’re reading this and will be there, be sure to say hi!)
